Data Anonymization at Scale
At Lunar, we continually strive to be at the forefront of data best practices. Data anonymization is one of these practices, and in this post, we will explore how Lunar builds and operates a state-of-the-art data anonymization engine to serve this purpose.
Why do we use Data Anonymization?
At Lunar we continuously produce data as part of our normal operations. A part of having this data is making sure it is safe for use and following regulations like GDPR. Data Anonymization is one such technique, it allows the other services to depend on the data while not being burdened with the Personally identifiable information (PII) that are often associated with this data. It not only makes it easier and safer to process data, but allows a complete inventory of all the data processed.
What is Data Anonymization?
Data anonymization is the act of altering parts of a data object related to a person, or another sensitive entity, such that the data remains useful but no longer personally identifiable. This act may be undertaken for various purposes and reasons, but generally, it aims to improve governance and control over data usage, making it easier and safer to utilize the data for analytical purposes.
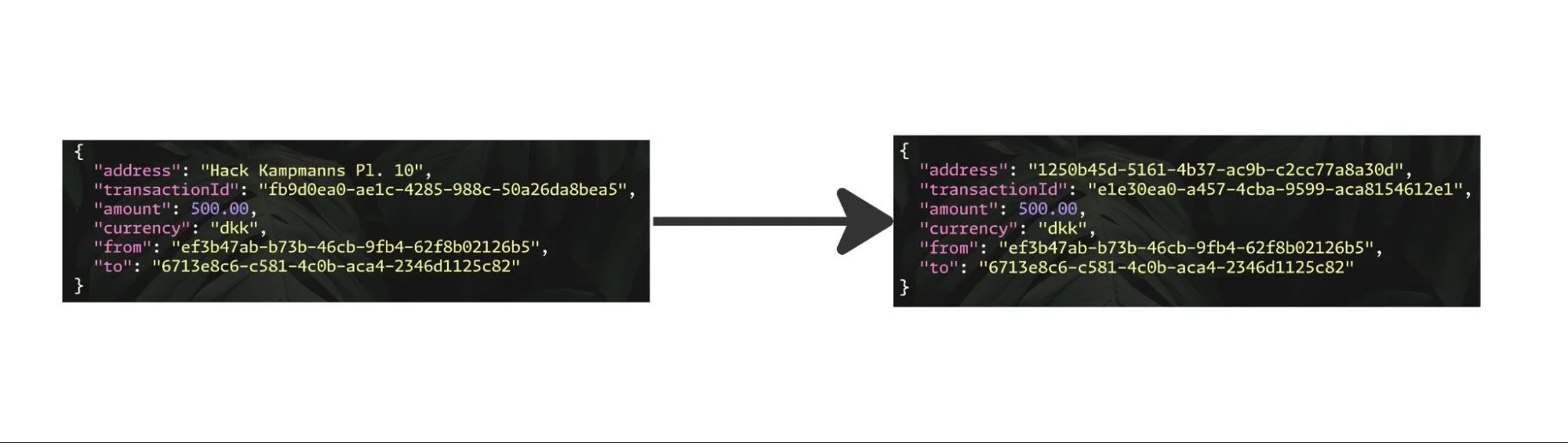
We can see an event having certain fields removed (address) and replaced with a token (uuid)
There are many ways to anonymize data; one method involves replacing sensitive elements with a token, while another mutates the data in place to retain a similar meaning, but without the ability to identify an actual person or object from it. For example, "Hack Kampmanns Pl. 10" could simply be generalized to "Aarhus."
Data anonymization pipeline
At Lunar, we have internally designed our anonymization pipeline with multiple stages:
Data Entry: Raw data arrives and is stored.
Tokenization: Data is processed, and sensitive data is extracted and replaced with tokens (such as the UUID mentioned above).
Anonymization: Data is either reintegrated into the original data objects or replaced with alternative information, depending on the use case and purpose.
Staging Area: The cleaned data is then placed in a staging area, from where it can be integrated into the rest of the data ingestion pipeline and fed into our data analytics platform.
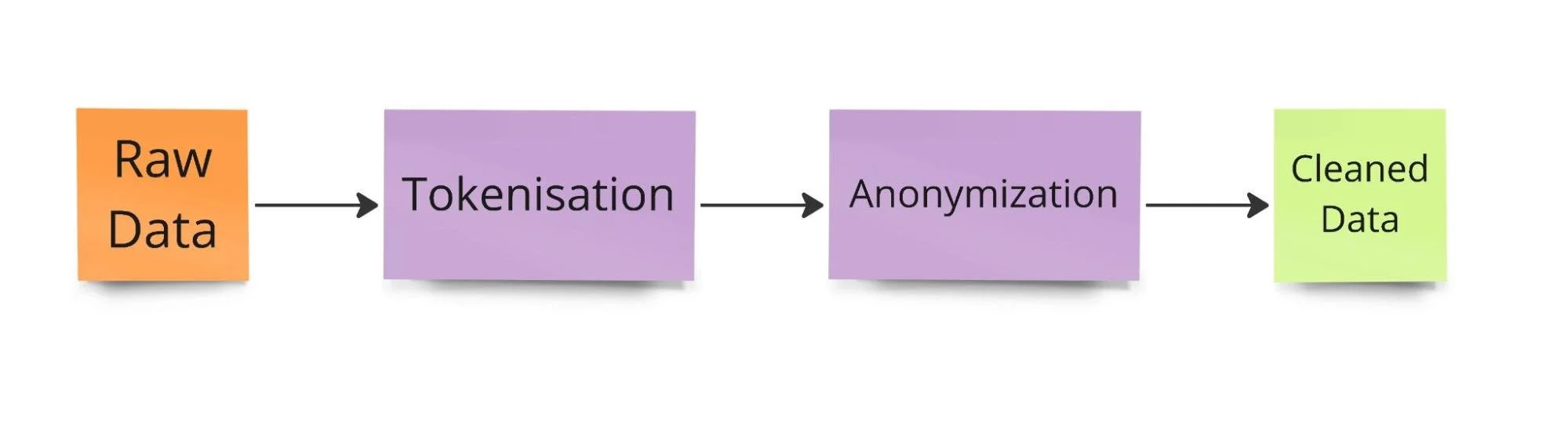
The 4 stages of data processing
In the following sections, we’ll dig into each of the above-mentioned stages.
Raw data
Raw data objects at Lunar adhere to a stringent and opinionated set of tools and follow a uniform format. Each object is encapsulated in an envelope that provides crucial metadata about the event, including a timestamp, a unique ID, and the originator. This metadata is essential for determining whether we have previously processed the event and which schema should be applied.
Additionally, events are partitioned based on their initial publication date. Our data anonymization platform is designed to handle time-traveling data seamlessly, treating it as a first-class citizen. It is not uncommon for our system to process an event published three years ago, applying the same or modified processing based on schema updates.
Our anonymization pipeline continuously scans our ingested data for any data it has not previously scanned. Upon identifying an unprocessed partition—a set of data objects—it schedules them for tokenization.
Tokenization
Tokenization is the act of replacing sensitive data fields with tokens, which are pointers. In our case, each token is a globally unique identifier (GUID) that points to a piece of data, with the sensitive data itself stored elsewhere for safekeeping. This process facilitates easier data management and cleanup.
Data arriving from the raw staging area has not yet undergone schema application, making it difficult to interpret its structure natively. The first step, therefore, involves applying a schema to understand and structure the data.
Schemas are already implemented elsewhere in our data platform, especially when event data is packed into Parquet files for our analytics platform. At this stage, we ensure that the data delivered to the analytics platform adheres to a schema and is no longer considered unstructured.
However, the same processing cannot be directly applied to all incoming data due to potential schema incompatibilities with certain data objects. Moreover, given the critical role of the anonymization pipeline, we cannot discard data that does not conform to the expected schema.
We have developed a custom token-sweeping algorithm that optimistically searches through data objects for fields marked as sensitive. This process does not involve applying the schema directly; instead, it navigates through the data, identifying fields of interest, replacing them with tokens, and then forwarding them further in the pipeline. This is possible because the events are protected against breaking changes elsewhere, allowing us to reason about the data's structure directly.
This entire process is executed under a single transaction setup for the scheduled partition. As such, we either complete the handling of the set of data objects or, in case of failure, restart the processing in the next tokenization loop. This method ensures the system's robustness, though it comes at the cost of latency and performance. While we cannot guarantee the exact timing of event processing, we ensure that each event is processed at least once. Thanks to the idempotency built into the tokenization step, encountering the same data twice results in identical tokens.
Once tokenization is completed for a partition, it is moved to another staging area, ready to be picked up by the anonymization step.
Tying tokens to an ID
Because sensitive data is subject to various legal requirements, we need a structured and systematic approach to determine when to retire specific fields. Regulations such as GDPR and PSD2 impose stringent rules on when to anonymize sensitive data, such as addresses and social security numbers.
During the tokenization step, we always link tokens to an entity. This entity could be a person or another identifiable unit. When it becomes necessary to retire an entity after a specified period, we simply mark the associated entity ID as retired.
Once an entity ID is marked as retired, our system automatically processes all data objects linked to that entity. These data objects are completely removed from our system. Concurrently, our anonymization engine processes the data, ensuring that it is securely and safely expunged from our analytics platform.
Anonymization
Currently at Lunar, our anonymization step is relatively basic. When we anonymize data, we replace sensitive data fields with the text “REDACTED”. In the future, we plan to develop more sophisticated strategies, as illustrated by the "Address to City" example mentioned earlier. The primary goal is to effectively extract and manage sensitive data without compromising its utility.
These enhanced strategies may include deriving a more generic address, generating a fake yet random social security number, or creating a general but unique IP address. Each method is designed to maintain the usefulness of the data while ensuring individual privacy.
The core of the anonymization process involves taking data objects that have been tokenized in the previous step and processing them with our data anonymization engine. This step either reconstructs the data as it would have appeared originally or inserts the anonymized data where sensitive data previously existed. This allows our data analytics platform to process the data as usual, although it will now encounter the placeholder “REDACTED” in fields associated with retired entities.
In our setup, the anonymization step is essentially the inverse of the tokenization step. It utilizes the same token-sweeping algorithm previously described to reintroduce the original values into the data.
Once this process is complete, the data partition is marked as requiring reprocessing. During the next cycle, our data ingestion pipeline re-ingests the cleaned data, updating the analytics platform with the latest information.
This might seem redundant as if we are simply tokenizing data only to recombine it later. However, the anonymization step can be triggered independently of the tokenization step and usually occurs when an entity's data needs to be retired. Therefore, it serves various purposes beyond just data recombination.
Cleaned data
The cleaned data is continuously backfilled into our data analytics platform. This process is triggered only for partitions that have undergone changes.
Additionally, the tokenized data partitions — before they have been anonymized or recombined — can be directly utilized if desired. This practice offers optimal data governance assurances.
As such data never contains sensitive information, it can be used for a broader range of analytical purposes without the risk of data leakage. This ensures a wider margin of utility while maintaining stringent security standards.
Built using standard Golang tools
Lastly, I'd like to discuss the development of our anonymization pipeline. Unlike typical data processing tools, this pipeline was developed using the standard Golang service tools that are fundamental to Lunar’s operations.
Data practitioners are likely familiar with tools like Kafka, Spark, and Flink, which are staples for data engineers. While Scala and Java are commonly used in these contexts, they are not the primary technologies at Lunar. Despite having capabilities in these languages, we chose to leverage Golang — the backbone of nearly 99% of all services at Lunar — for this complex, multifaceted pipeline. This approach allows us to utilise our established strengths and infrastructure.
This approach also showcases the capabilities of our Golang service preset. It demonstrates how we can scale to meet demand, ensure fault tolerance, and run on our Kubernetes container runtime. We also leverage Prometheus and Grafana to drive metrics and analytics. Finally, PostgreSQL is utilized for consistent data storage and management. This combination of technologies illustrates the robustness and versatility of our system.
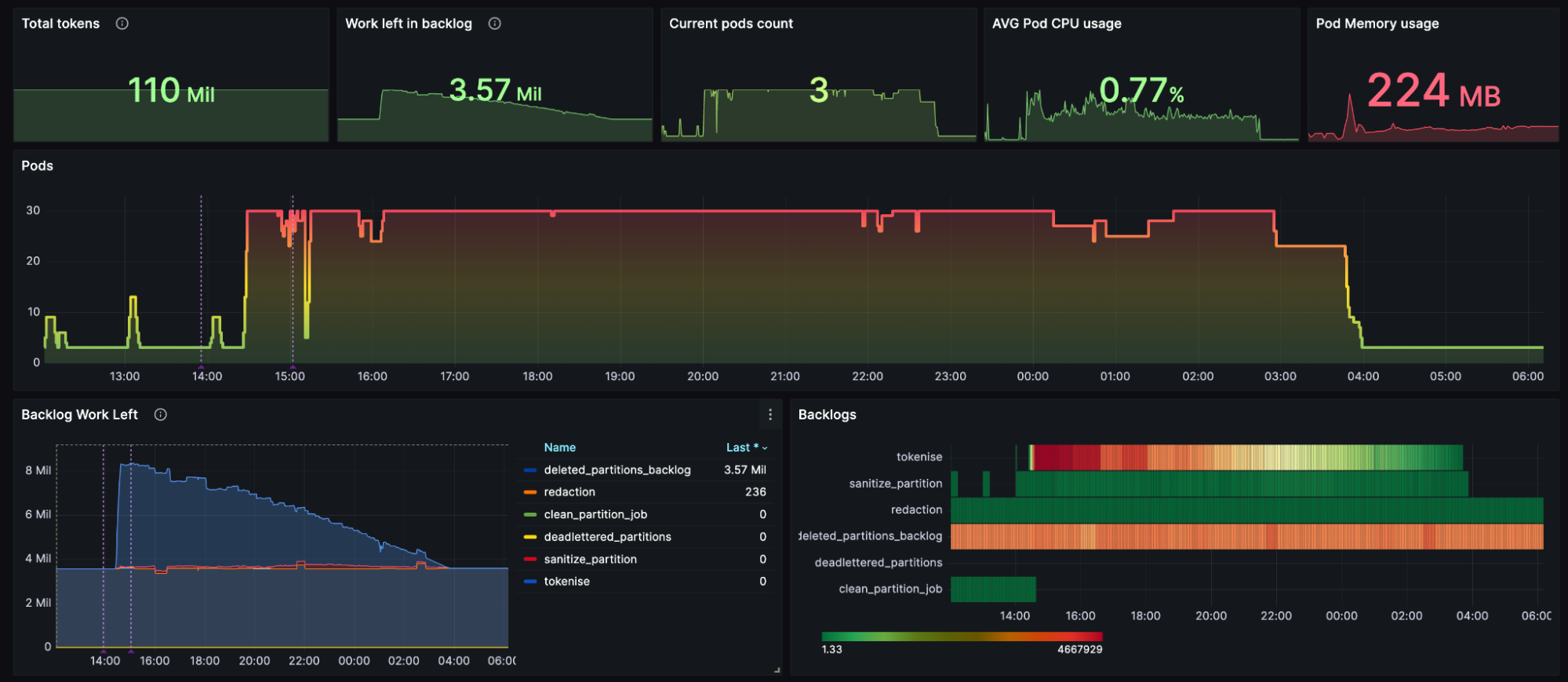
Overview of data anonymization solution, it is visible how much work the pods are doing, as well as where the work lies in the pipeline
The diagram above illustrates our typical setup of running three pods, which is the minimum default configuration. These pods operate efficiently, requiring no further scaling down. However, our horizontal pod autoscaler is set to a maximum of 30 pods, allowing us to scale up significantly during peak processing times when the system is initially activated.
Additionally, we utilize an estimate from PostgreSQL to monitor the backlog of partitions needing processing and to determine at which stage the bulk of the work is occurring. It’s important to note that the names of the stages mentioned in this article differ slightly from their operational names:
"Redaction" corresponds to "Tokenization"
"Sanitize partition" corresponds to "Anonymization"
While not all stage names are detailed here, each plays a crucial role in ensuring safe operations and in the retiring or processing of these partitions.
Choosing Golang proved to be an excellent decision for efficiently processing a vast amount of data. Each pod operates with an average of 224 MB of RAM and is capable of handling partitions up to 120MB in size. Our design goal was to ensure that each application runs as efficiently as possible, allowing them to operate alongside our standard applications without consuming excessive resources.
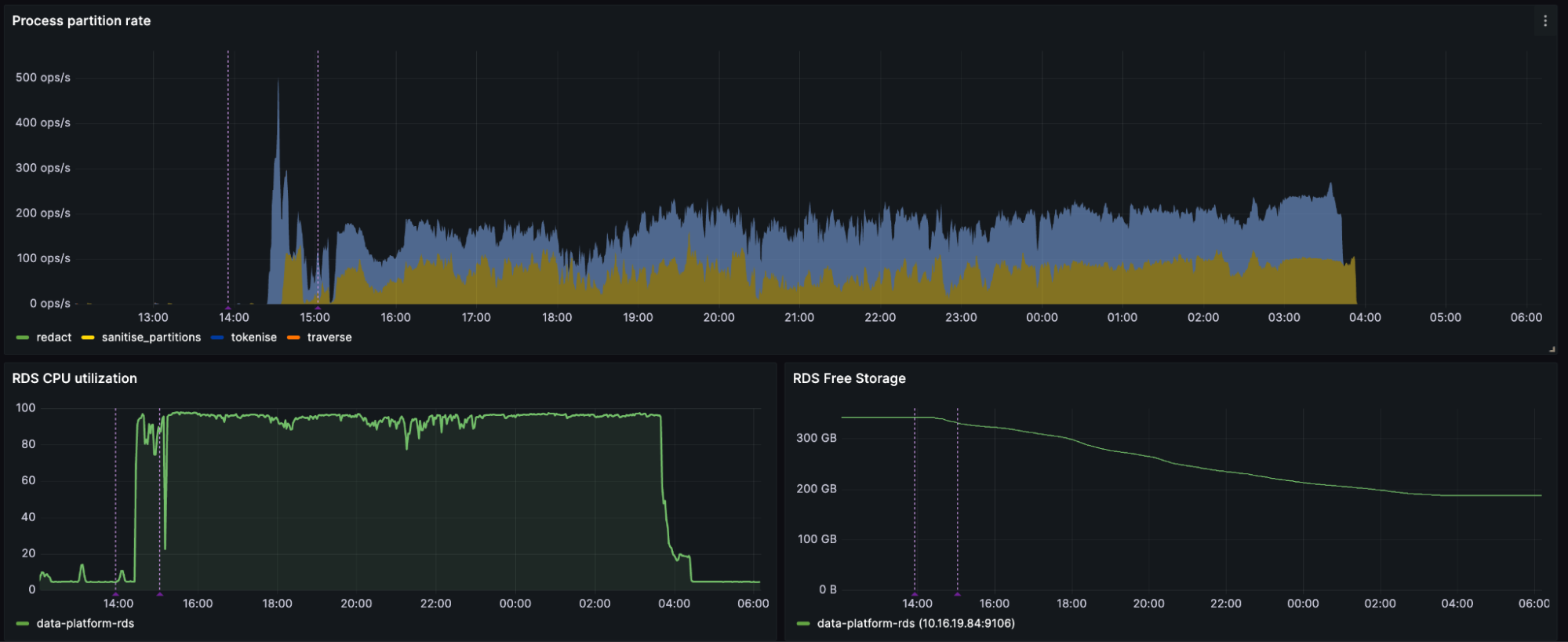
Overview of how fast partitions (unit of work) are processed, as well as the database utilization
To manage our backlog and ensure an "at least once" guarantee for our data, we utilized PostgreSQL as both our consistency mechanism and data store. During periods of heavy usage, we maximized resource utilization on AWS RDS (PostgreSQL), which occasionally became our bottleneck. However, this was primarily an issue during the initial data ingestion phase. Under normal operational conditions, AWS RDS performs efficiently, maintaining ample capacity even on smaller instances.
Since launch
The data anonymization pipeline has been fully operational for approximately four months and has reliably handled our partitions with only minor issues and no downtime, thanks to our 'at least once' guarantee. It has also been instrumental in testing experimental tools for connecting to RDS. Despite occasional issues such as random disconnections or connectivity failures during development, the system autonomously recovered to a satisfactory level, eliminating the need for manual intervention.
Conclusion
In this article, we've outlined Lunar's approach to processing sensitive data and upholding the highest data management standards. Our experience demonstrates the advantages of developing custom tooling tailored to specific needs, which often simplifies complex problems. By choosing Golang over more traditional platforms like Kafka, Spark, and Flink, we've shown that alternative technologies can not only meet but sometimes exceed the capabilities of conventional data processing ecosystems. This approach has enabled us to achieve robust data anonymization with enhanced efficiency and reliability.