From Rails Monolith to Microservices
NOTICE: Originally posted on March 20th 2018. We were known as ‘Lunar Way’ until late 2019.
In earlier tech focused blog posts a number of my colleagues have talked about aspects of the Lunar Way platform and the organisation of the tech team building it.
The term “microservice architecture” either explicitly or implicitly played an important role in these posts:
In Lunar Way’s journey towards true autonomy (Part 1) the focus was on the ability to organise tech teams in to highly autonomous feature squads. This would be a lot more difficult if we did not have a microservice architecture.
The ease with which we adopted a new language (Go) into our backend tech stack, as described in Adopting Go at Lunar Way, was only possible due to our microservice architecture.
Lunar Way’s journey towards Cloud Native Utopia focused on our introduction of Kubernetes and other technologies from the cloud native landscape. A fundamental reason for introducing a cluster orchestration framework like Kubernetes was specifically to enable independent deployment of individual microservices.
In this post I will dive deeper into exactly how we use microservices at Lunar Way.
I will also explain why we have chosen this type of architecture and what it allows us to do.
The post will be a bit like a traveller’s report of a journey from a monolithic backend architecture to microservices. Along the way I’ll describe some of our discoveries and hopefully there’ll also be some takeaways about the best approach and pitfalls that’ll be helpful if you’re setting out on a similar journey.
Microservices. What is it?
Before we get to our microservice journey, let’s get some terminology defined. What is a microservice architecture in the first place?
There is no precise definition, which everyone in the industry agrees upon, but for the purpose of this post we will use the following characteristics, which hopefully everyone will agree upon is some of the basic characteristics of a microservice architecture:
A microservice architecture is an application design, where a number of independent, small services work together to achieve the purpose of the application. Each service must be independently deployable and have a clear, coherent purpose in the sense that it must be possible to describe it as doing “just one thing”. The services must communicate through well defined, simple communication protocols and they should only share data through these protocols.
Typically, a microservice is designed as the owner of a specific data domain and the service implements the business rules and interfaces related to this data domain. This is what is called the “bounded context” of a microservice.
Event based systems and asynchronous communication
A microservice is never alone. An application is typically made up of tens or hundreds of services, and these services must communicate somehow in order to fulfill the purpose of the application. You can choose to use synchronous communication between services by using some kind of RPC in the broadest sense (think REST, gRPC or a similar technology).
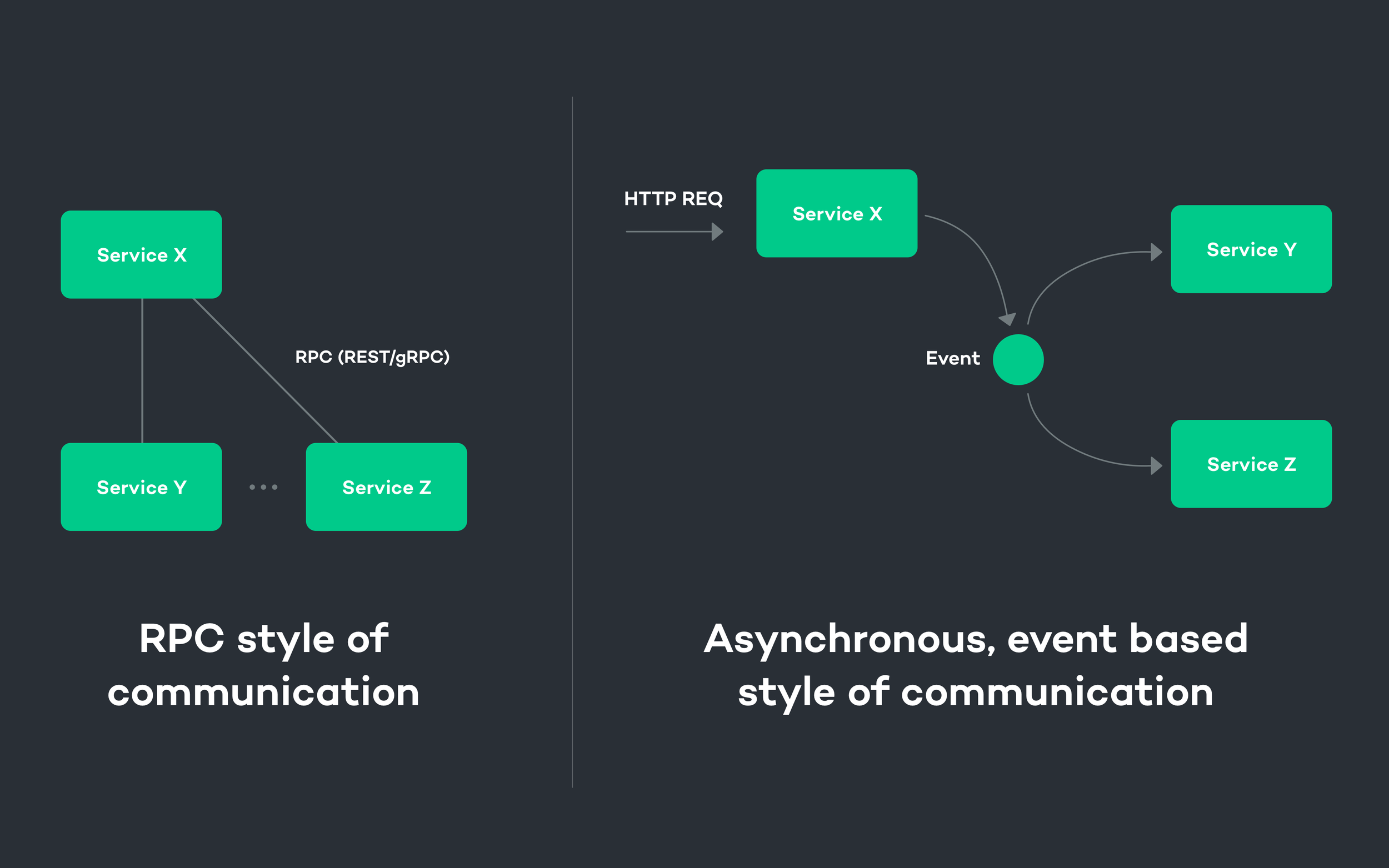
However, no matter which RPC method you choose, the RPC call introduces a tight coupling between the two communicating services, a coupling both at compile time and at runtime. At runtime, the coupling spans both space and time. This means the receiving service must be up and available for the sending service to reach it.
This coupling is bad for many reasons. For example, if service B is down or unreachable, you still want service A to be able to work, although it may not be able to fulfil its purpose completely.
This is why when you say microservice, there’s a good chance the next tech buzzword coming out of your mouth will be “event sourcing” or “asynchronous communication by message passing”.
If the synchronous communication between services is changed to an asynchronous one, the tight coupling between the services at runtime is removed and reduced to a dependency only involving the data in the message. Service A can broadcast its event to a queue and it does not matter if service B is not immediately available to process it. Eventually, when service B is up, it will process the event and perform whatever action it’s designed to carry out.
Asynchronous communication using events opens up a number of other significant possibilities:
Open ended communication
Broadcasting messages, i.e. publishing events without an explicit receiver and free for everyone to consume makes it easy to implement new services, which make use of already existing events.
Event sourcing
If all business model modifications are broadcast as events and these events are recorded, you get a log of all changes to the system.
Essentially, you get the complete history of the system in a single source.
This is the fundamental idea behind event sourcing, an architecture where all changes to data are stored as events, which may be replayed to get to the current state of the system. This design is often combined with microservices since it also offers a model for how a service may gain knowledge about a business domain outside its own domain — it can simply subscribe to all relevant events and build its own view of that domain.
What are the challenges?
There’s no such thing as a free lunch!
This is also true when it comes to microservices. In many ways, building a functioning microservice architecture is a lot more difficult than building a monolith.
You must consider the following questions when embarking on building a microservice architecture.
Data duplication
If service B needs to know something in a domain which is owned by service A, how does it get this knowledge? Should it do a synchronous RPC request to service A each time it requires this knowledge? Or should it instead subscribe to business events from service A and build its own model of the world, as described above?
Service domains
How do you divide your services and organize the communication in order to avoid building a distributed monolith with a huge amount of dependencies between services?
Debugging and tracing
How do you debug and trace across service boundaries?
Asynchronous communication
Adding asynchronous communication to the equation makes it even more complex. How can you be sure events are consumed correctly? In the case where a certain business workflow is implemented across several microservices involving multiple asynchronous events, how can you be certain the flow is completed, that it does not stop somewhere down the chain due to an event being lost?
What are the benefits?
Why dive into this challenge when it’s all so complicated? The answer is very much centred around different aspects of scalability and independence:
Runtime/deployment
In combination with a clever deployment tool, microservices provide the ability to scale services independently of each other. Services with a high load or costly processes can be scaled and deployed independently of other services.
Microservices have an inbuilt resilience to faults — an error in service A does not prevent service B from functioning.
Microservices fit nicely into a continuous delivery mindset where services are deployed continuously in order to minimize work in progress.
Development
Microservices allow for autonomous teams which can build and deploy services independently of each other.
Microservices allow for fast experiments to quickly try out and evaluate new ideas to lower time to market.
Microservices naturally encourage a system design with high coherence and low coupling, where different parts of the code base only interact through well defined interfaces.
Lunar Way’s microservice architecture
With the terminology, concepts, challenges and benefits well defined, we can continue with Lunar Way’s journey towards a microservice architecture.

When I joined the company back in early summer 2016, the backend consisted of a single Rails application. The API exposed by the backend to the app was nicely divided into domains, but the code and data model was tightly coupled. During the summer we decided to embark on rebuilding the backend into a scalable architecture, allowing us to meet the requirements of the business and to be able to deliver new features fast.
There was really no doubt that what we wanted was ultimately to kill the Rails monolith and build a microservice architecture instead.
Furthermore, we wanted as much as possible of the communication in the platform to be asynchronous. At that point we did not have answers to all the challenging questions posed above. However, we thought the benefits of a microservice architecture were too significant to ignore, and hoped we would be able to solve the challenges along the way.
Our first “microservice”
The first microservice we built was the so called “Feed service”. Its sole purpose was to supply the app with a feed of transactions and other items displayed alongside transactions in a chronological order. Up until then, the data model used for the data displayed in the app was very tightly coupled to the data model in the Rails backend. This was an obstacle for data model changes on both sides. It was therefore also a main goal of the feed service to decouple the data model of the app from that of the Rails backend, by letting the feed service implement a new, simple API for the app centred around feed items.
The feed service was supposed to generate feed items based on data received in events published by the Rails monolith.
This was where we made our first rookie mistake
Instead of embedding the complete transaction data for the feed items into these events, they only contained a unique identifier of the transaction, and the feed service would then have to look up the actual transaction in the old Rails database. In hindsight this was a really bad decision, which created a very tight coupling between the feed service and the Rails monolith at the database level. It goes against all the principles of microservices being independent and only sharing data through well defined communication protocols, and certainly not by letting one service read from another service’s database.
The main reason behind this bad design choice was to buy ourselves some time. Due to technicalities, which are beyond the scope of this post, it was the easiest solution at the time, although we knew it wasn’t the best choice.
We have regretted the shortcut ever since. The time we won back has easily been lost due to the coupling it introduced.
The first key takeaway: Never, ever let one microservice access another service’s data directly.
The journey will continue soon in my next post. Stay tuned!
NOTICE: Originally posted on March 20th 2018. We were known as ‘Lunar Way’ until late 2019.