GitOps - Operations by Pull Request
NOTICE: Originally posted on March 10th 2020.

For the past year, or so, we have been investigating, built PoC's, discussed options, decided on a model, and actually implemented a GitOps model at Lunar.
This blog post will walk you through our considerations, the different models we see in the current ecosystem, and the model that we decided to implement.
Prerequisuites
But before diving into the details, let's first discuss a couple of terms and definitions, to make sure we are on the same page.
GitOps is an opinionated implementation of Continuous Delivery.
Continuous Delivery (CD) refers to the practice of being able to quickly and sustainably get changes into production and extends continuous integration by automating the release process, so that you can release your application at any point in time.
Continuous Deployment (CDE) goes one step further, by automatically releasing every change that passes the workflow of your production pipeline.
The last term I would like to discuss before moving into the details of GitOps, is reconciliation.
If you look up the term reconciliation in a dictionary, you will get something like this:
“the process of making two people or groups of people friendly again after they have argued seriously or fought and kept apart from each other, or a situation in which this happens”
or the more generic definition,
“the process of making two opposite beliefs, ideas, or situations agree”
By this definition, it referes to two different views agreeing and to become one.
In the context of Kubernetes, you have probably encountered this concept when applying a Deployment to your Kubernetes cluster. In Kubernetes, we specify a desired state in our yaml resource files or using kubectl, an example of this could be
replicas: 3
With this statement we tell Kubernetes that our desired state is 3 instances of our application. It's now the job of the Kubernetes controller-manager to try and make the two different states agree, hence drive the desired state to be the current state of the cluster.

Ok, now that we know what reconciliation means, let’s see how this concept applies to GitOps.
What is GitOps?
The term GitOps was coined by Alexis Richardson, CEO of Weaveworks a couple of years ago.
They define the term as:
GitOps is a way to do Kubernetes cluster management and application delivery. It works by using Git as a single source of truth for declarative infrastructure and applications. With Git at the center of your delivery pipelines, developers can make pull requests to accelerate and simplify application deployments and operations tasks to Kubernetes.
To put it in one sentence;
GitOps is leveraging git as the source of truth to reconcile applications and infrastructure.
In order to be able to use git as the source of truth, we need a way for the cluster to detect and apply changes to the cluster. We need a controller with a reconciliation loop running somewhere looking for changes in the desired state, and drive the current state towards the source of truth. Let’s call that cluster reconciliation and could look something like this:

Now, in order to make changes to your cluster, you create a PR with the desired changes, and commit that to your cluster configuration repository. Eventually your changes will be detected and the control loop will drive your cluster towards the desired state.
You might be thinking, this seems like an unnecessary extra step, and further, what is wrong with just using kubectl apply either directly from local machine or in a CI/CD pipeline?
Many people, us at Lunar included, built their first pipelines to Kubernetes with some simple scripts to generate Kubernetes yaml, and apply the changes to Kubernetes using a simple kubectl apply from the CI/CD server.
However, this approach came with quite a few caveats and problems. The asynchronous nature of the controller-manager makes it hard to detect when a container in a pod is actually ready to receive traffic. You can come a long way with using the kubectl rollout status in your pipeline to wait for pods to be in Running state, but what happens when the container crashes 5 seconds later, because it can't reach the database? It's possible to implement a loop in a script that can detect these failure modes, but wouldn't it be much better if you just get a message when this occurs?
This way of doing it, works to some extent, and was a good place to start for us. But it came with drawbacks highlighted below:
The CI/CD system needs pretty permissive rights to your clusters. From a security standpoint, this might be a no-go.
Executing
kubectlfrom a CI/CD system is a very imperative and commanding approach, instead of the declarative approach that is used in many aspects of the Cloud Native ecosystem.All Kubernetes yaml was generated using shell scripts in the pipeline and dismissed once applied to the cluster. This made it very hard to track the diff between what was running and the new desired state. As a financial institution we need to be able to audit every change, and this implementation made that hard.
No single source of truth of what was actually runnning in our clusters. In case of a cluster going down, it would require us to run through all services and generate new configurations, which would take time, and be error prone.
In this section, I’ve provided you with an introduction to GitOps, and some reasoning behind choosing this approach from out standpoint at Lunar. Next, let’s look at the different options available.
Flavours of GitOps
Back when we decided to look at the different options of how we could implement GitOps at Lunar, these were the approaches we saw. I have named them and will in the next part of this blog post go through them one by one.
Decentralized One-way flow
Decentralized Two-way flow
Centralized flow
There are no formally accepted naming of these different architectural approaches but to make the discussion clear and referable these are the names that will be used.
Decentralized One-way flow
The first approach we will look at, is what I refer to as the decentralized one-way flow. The following diagram provides an overview of the flow. The main thing to note, is where the controller is running, and how it gets its updates.
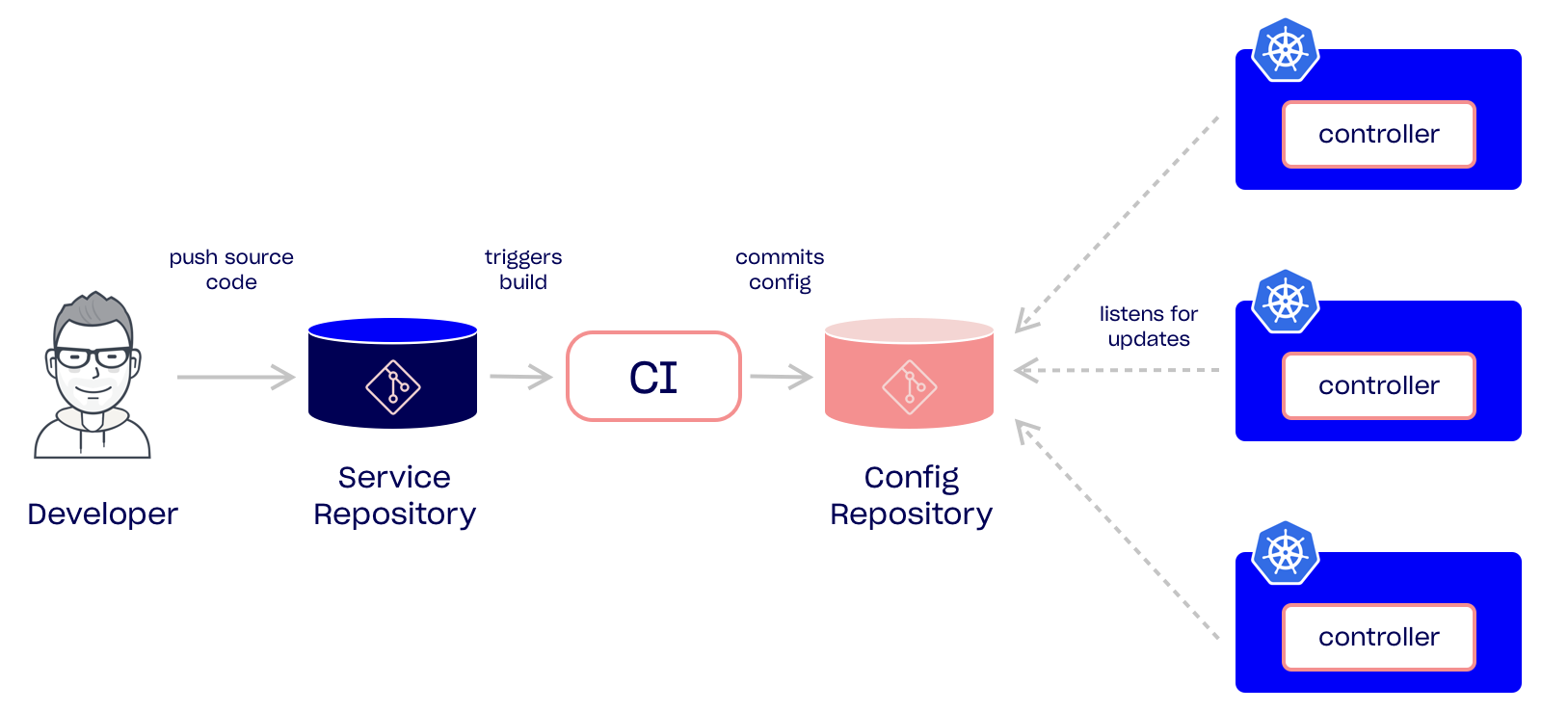
Let’s go through it step by step. A developer pushes a change to a service repository (assuming you are using a polyrepo strategy). This push triggers a continuous integration job that will build, test, scan, push, and generate the Kubernetes configuration. Instead of applying this configuration directly to the cluster, it pushes the config to a centralized repo. A controller running in the Kubernetes cluster detects a change in git, either by polling or using webhooks, and applies the change to the cluster. The idea in this approach is to use the config repo as the trigger for new changes. Further it gathers all configuration for a given service in the service repository.
Decentralized Two-way flow
The Decentralized Two-way flow is the flow that Weaveworks and the flux-cd project highlights.

This flow is a bit different from the Decentralized One-way flow in that a Docker registry is used as a trigger for new deployments, and the controller has the ability to update the config repo, based on the newly built image.
Further, this flow separates configuration from the source-code, meaning that if you want to make any configuration changes to your service, e.g. change an environment variable, you have to create a PR against the config repository.
The flow starts with a developer pushing a new change, a CI server picks up this change, builds, tests, scans, and pushes an image to a docker registry. This triggers a controller in the cluster to apply the changes, and commit the updated deployment specification back to the configuration repo. If a developer or operator at some point has to change configuration for a given service, this has to be done in the config repository. This gives operators a great benefit as they can manage all configurations in one central place. In this setup the controller needs a read/write access to the config repository, whereas the one-way flow only requires read access.
Centralized flow
The last flow I will highlight in this blog post, is what I refer to as the centralized flow.

The idea in this flow is similar to the other flows. A developer pushes a source code change, a CI job builds, generates configuration, and pushes the configuration to the config repo. Next a centralized control-plane running in a centralized environment detects the change, and applies the state in the given environment. As you can see in the diagram below, we now have one component controlling the rest of our environments. This requires a centralized controller which have access to the Kubernetes API’s in the environments it needs to control.
Where should service configuration live?
In the previous section, I provided a brief overview of the different flows, or architectural choices you need to decide on before embarking on a GitOps journey. An important differentiating factor between the 3 flavours of GitOps, is the question: Where should service config files live?
We’ve had many discussion internally at Lunar about this exact question, and we decided to put everything in the service repository. The reason for this decision is found in an ongoing mission - namely to reduce the operational overhead put on developers and services, and provide tooling that abstracts many of the nitty-gritty details away. We do not have a centralized operations team, or release team, and it's therefore of the utmost importance, that developers can build and run their services by themselves. The way we do this today is by using another open source project we built called shuttle.
shuttle abstracts things such as Dockerfiles, Kubernetes yaml, common tooling, etc. and provides a CLI entrypoint that all services uses. Each service repository is using, what in shuttle terms, is called a plan. A plan is a set of centralized scripts, templates, etc. that is available for the given service using the shuttle CLI and a config file called shuttle.yaml. This file contains metadata about the service, but also how e.g. environment variables, some Kubernetes configurations or similar should differ between our environments.
shuttle will handle the rest and generate Kubernetes yaml files based on this simple yaml file. These files can now be committed into a config repository and applied by a controller.
How to deal with multiple environments?
As you probably have encountered now, there’s many ways to implement a GitOps approach. A question you definitely will encounter when embarking on this journey is: how to deal with multiple environments?
You have quite a few options, when deciding on how to deal with multiple environments:
Multiple git repositories each representing an environment
One git repository using branches to represent an environment
One git repository using directories to represent an environment
Keep the configuration in the service repository
The choice you have to make here, very much depend on whether you want to use an already accessible GitOps solution, like Flux CD with Weave Cloud, or Argo CD, or maybe build your own tooling to support this.
Either way, you need a place to store your configuration, and a way to move configurations between environments.
GitOps at Lunar
In the previous section on “Where should service configuration live”, I provided some hints to how we at Lunar chose to architect our GitOps setup. In this section I will try to go a bit deeper, and touch upon the reasoning behind our choices.
Let’s first start with the big question: why use GitOps at all? There’s a couple of reasons why we thought this way of doing it was appealing. As you may know, we are building a bank. In this context, there are many requirements and regulations that we have to live up to. One of them being audit logging. Who did what and when? We need to be able to answer this question at all times.
Another reason or goal we had upfront was that we needed a good way to limit access to the environments - without losing too much agility. We walk a fine line, balancing speed and agility against compliance and security.
The last reason I will highlight in this section is disaster recovery. We need to be able to bring back our environments in case something goes terribly wrong, and we need to be able to do that easily and without shaking hands. It should in theory be a non-event if a cluster dies.
These three reasons were the main reasons why we found GitOps interesting.
Our solution
One of the first decisions we made was to go with a one-way decentralized flow. The reasons for this, as I explained earlier, are that we want to focus on the ease of use from a developer perspective. They are the ones who day to day uses the tooling, and it needs to support their workflow and help them become effective. This was as mentioned also the reasoning behind choosing to have all service configuration in the service repository.
The next decision was to decide whether we want the controller to commit back to our config repository, or not. We really like the simplicity of using the git repository as the trigger for new deployments, and disliked the fact that the controller could commit changes in our config repository. We felt more in control with a one-way flow.
We choose to use Flux CD as our controller. Flux works great and is easy to setup and configure to be used in the flow that we wanted. Flux runs in each of our environments and is configured to listen for changes in a specific directory of the config repo. We have configured flux to be read-only and to not listen for changes in the docker registry, and thereby only react on changes in the given directory of the config repo.

But, the big question for us, was to find a way to move the configuration files between the different directories (environments) that flux listens on, e.g. how do we move a deployment from one environment to the other?
We couldn't really find an answer to this question in the market or in the open source community. At least not a solution that fits our needs. Instead we set out to build our own “release manager”.
Release-manager
The release-manager project consists of 4 components.
release-manager server
release-daemon
hamctl
artifact
The release-manager server is the heart of the system, and is the central point of contact. It receives webhooks from git, the release-daemon, and further the CLI, hamctl, also interacts with it.
You might be thinking, why did they name their CLI tool after pink meat? Actually Ham was the first chimpanzee in space As you might have noticed, we have a space theme going on at the office.
The server is responsible for moving files around in the config repo, e.g. releasing artifacts to environments. artifacts in this context refers to kubernetes yaml for each of the given environments along with metadata.
In the following I will go into a bit more detail to explain each of the four components.
release-manager server
The release-manager server's primary job is to move artifacts to their destined environments. It acts based on a couple of different events. The CLI, hamctl, talks to the server to either get information or change state. When a new artifact is pushed to the config repo, the release-manager receives a webhook from GitHub to notify about the change. The release-manager then checks to see if there exist an auto-release policy to any environment, and if one exists, it will release the artifact to the given environment. If no policies exists, it will do nothing. Currently there exists two ways of releasing an application, promote or release.
The promote event will release software based on an implicit notion of the environments, in our case it’s;
master > dev > staging > prod This means that, if you instruct the release-server to promote to environment staging, the release-manager will figure out which artifact is running in dev, and move that artifact into the staging environment.
The other possible event, release, can either release based on a specific branch or an artifact-id. This allows developers to release a specific branch to a specific environment.
release-daemon
The next component we will discuss, is the release-daemon. The responsibility of the release-daemon is to report state changes from the given environment back to the release-manager server. It works as a Kubernetes controller running in each of the environments, and listens for changes of deployments and report each of the pods’ states back to the release-manager. If the release-daemon sees a pod crash, either by CreateContainerConfigError, or CrashLoopBackOff, it will fetch the latest loglines of the container before reporting back to the release-manager.
hamctl
The third component, is the CLI-tool, hamctl. This is how our developers interacts with the system. If a developer wants to promote a version of their application, they can do that using hamctl, as follows
hamctl promote --service example --env staging Besides the promote method, developers can also release their applications using the release command. Let’s say I have a hotfix on a hotfix branch, and I need to release this into staging for testing.
hamctl release --service example --branch hotfix --env staging The CLI also has a couple of other functions such as getting status from a specific service, e.g. which artifacts are deployed to the different environments. Policies can also be controlled using the CLI.
artifact
The last component, is the artifact CLI. The main idea behind this component, is to gather information from the CI pipeline, but is also responsible for reporting CI status to Slack.
artifact produces a json-blob called artifact.json. At each step of our pipeline, a call to artifact is executed to report the state of that step. This state change is written to the json-blob and reported to the git-author via Slack.
This was a fairly brief overview of the system we have implemented at Lunar. All code for our release-manager solution is publicly available in our GitHub account.
Let’s revisit the three reasons why we wanted GitOps; audit logging, limited access to environments, and disaster recovery.
With the system we currently have deployed, we now have all the audit logging needed. All interactions with our systems are logged using commits, and can be found in the git history. Secondly, all releases are decoupled from our Kubernetes environments, which means our developers don’t need access to the environments. Lastly, all our environments are now stored in git at any given time, which makes disaster recovery a lot easier.
Everything in Git
You have now seen some of the different options in implementing GitOps, and also our specific implementation. I want to wrap up this blog post with a teaser for a possible upcoming blog post.
We are working towards a scenario where we want to leverage the Kubernetes API, and Kubernetes extensions, Custom Resource Definitions, to have even more of our infrastructure declared in git.
This could be creation of databases, users, but also cloud resources, such as AWS S3 buckets, and even machines.
I hope this blog post offers some perspective of the different choices you have when implementing GitOps, and also provides reasoning why this approach might be a good idea, especially in highly regulated environments.
NOTICE: Originally posted on March 10th 2020.