Migrating to Flux v2
NOTICE: Originally posted on January 19th 2022.

Our migration journey from Flux v1 to Flux v2 was not as straight forward as we had hoped, and we wanted to share some of the learnings we got during the migration.
At Lunar we name everything based on a space theme and Nasa in this context is a platform squad with the responsibilities around our developer and container platform. We work on improving the platform and everything around it. In this case we wanted to migrate from Flux v1 to Flux v2.
Defining terms
What is GitOps
Quoting WeaveWorks on GitOps :
“An operating model for Kubernetes and other cloud native technologies, providing a set of best practices that unify Git deployment, management and monitoring for containerized clusters and applications.” - WeaveWorks GitOps definition
Kasper Nissen wrote a great blogpost on GitOps - “GitOps operations by pull requests”
What is Flux v1 & v2
One big difference between Flux v1 and v2 is that Flux v1 is basically a simple loop that does kubectl apply on a given pool of manifests. It's a controller running in Kubernetes that watches a Git repository and sequentially applies the resources. This is all done by one process.
Flux v2 on the other hand is split up into multiple processes. One is in charge of fetching Git repositories, another for sending notifications when events happen, and another to reconcile. Learn more about Flux.
Flux v2 is also capable of using Kustomize which adds support for both overlays and defining resources for a given service. However, currently, we do not use the overlay functionality as we have a folder for each environment in our Git repository.
What is Kustomize
Kustomize is an alternative to Helm that can create overlays, define resources and patches without using templates.
To quote Kustomize :
“Kustomize introduces a template-free way to customize application configuration that simplifies the use of off-the-shelf applications” - Kustomize.io
Flux v2 can be pointed to a Kustomize file and reconcile the service defined in that Kustomize resource. This Kustomize file might point to other Kustomize files with more resources or patches that need to be applied to the data.
Mono/multi repo
Defining services and environments in Git you basically have two options. Either you have a Git repository for each service, resulting in a lot of Git repositories - multirepo, or you have all manifests in one big Git repository - monorepo. We have historically been using a monorepo with Flux v1 and automation in front of it to avoid drift in definitions between environments. This has worked fine in the past but will be important later on in the blog post.
Shuttle
In Lunar, we use Shuttle to centralize our CI pipelines.
“shuttle is a CLI for handling shared build and deploy tools between many projects no matter what technologies the project is using”
Shuttle uses the concept of a Plan which defines what Shuttle can do. Each micro-service references a plan.
Release Manager
Release Manager is a CLI for managing releases to a GitOps Kubernetes repository. It enables developers to release artifacts into a GitOps mono-repo using a single command.
Current pains
Flux v1 deprecation
As Flux v2 was released, Flux v1 was soon deprecated. This means that all new development will happen exclusively on Flux v2 in the future. So we needed to either migrate to Flux v2 or something else to keep getting features and updates.
Duplicate definition
If two Kubernetes manifests are created with the same name in the same namespace, the API-server will reject the latter object from being applied. The big problem with Flux v1 is that it will stop reconciling any manifests from this point on in its queue. So, if one of the first objects happens to contain a duplicate definition, none of the services from that point on will be applied. This was a big problem for us as it basically prevented all squads in Lunar from releasing services.
Flux v1 does not support bulk-heading between deployable units. So one failure will block all other services.
Our monorepo grew and flux got slower
As our Git repository grew in size, Flux v1 naturally got slower at reconciling the entire repository. Flux v1 has a single process applying manifests to Kubernetes and the only way to scale it is vertically by adding more RAM and CPU.
Fix in Theory
Flux 2 is made to scale
One of the big differences between Flux v1 and Flux v2 is that the new version is split up into multiple processes doing one thing well.
These are:
Source controller
A controller's role is to watch a source defined. This is typically a Git repository, but could also be object storage buckets, etc.
Kustomize controller
Reconciles the cluster state from multiple sources (provided by source-controller)
Helm controller
Watches for HelmRelease objects and generates HelmChart objects
Notification controller
The controller handles events coming from external systems (GitHub, GitLab, Bitbucket, Harbor, Jenkins, etc) and notifies the GitOps toolkit controllers about source changes
Image automation controller
The image-reflector-controller and image-automation-controller work together to update a Git repository when new container images are available
Learn more from Flux's components documentation.
We currently use a Source controller, Kustomize controller, and Notification controller.
By splitting the capabilities of Flux 1 into multiple processes, Flux v2 is by design able to scale to running on various machines and scaling their resources independently.
Kustomize as a protocol
We choose to use the Kustomize controller, where we create Kustomize CustomResources (CRs) in Kubernetes that define our services. One Kustomize file per service. This is now how services are registered with Flux. So you could say that Kustomize is now our standard way of defining a service's resources.
Kustomize has several features. One of them is templating which we currently do not use. Another is that you can create a reference in one Kustomize file to another Kustomize file. This is used to have one Kustomize file per environment - and this Kustomize file refers to the services that should be running in the environment by referring to their Kustomize file. Another feature is that you can define dependencies in Kustomize, which Flux will consider when deciding the order of the reconciliation. One case could be that RabbitMQ is deployed before our micro-services are deployed.
Automating kustomize in plans
As of January 2022, we have roughly 250 micro-services running on our platform. Each of these has its own Git repository and a folder in each environment with its Kubernetes manifest in our mono repository. None of these had a Kustomize file, so we had to automate this.
First, we created a script that would go through the entire folder structure in our mono repo and create a basic Kustomize file (see service-a-kustomization.yaml in example below). This enabled us to start deploying our services to a given environment.
Second, we added a step to our pipelines for each service, that would ensure the desired Kustomize state would end up in its Kustomize file in the manifest repository.
And third, we added logic to our release manager that ensured that kustomize files would end up in the right location as we keep them seperate from our Kubernetes manifests.
GitOps-repo
.
|__ clusters
| |__ dev
| |__ serviceA
| | |__ service-a-kustomization.yaml
| |__ serviceB
| |__ service-b-kustomization.yaml
|__ dev
|__ releases
|__ serviceA
| |__ deployment.yaml
| |__ service.yaml
| |__ ingress.yaml
|__ serviceB
|__ deployment.yaml
|__ service.yaml
|__ ingress.yaml
Observations
Monorepo was really slow
It turned out that when ever our monorepo was updated with a new release Flux v2 had to go through each and every Kustomization.
Reconciling a queue took roughly 8 minutes with this default setup. This means that from a developer pushes a new release to an environment in Git, it can take up to 8 minutes before it gets in a running state. This is in contrast to the old Flux v1 setup where it took about one minute from a Git commit to the service was running.
In our Grafana dashboard for Flux v2 we could see the queue depth and work queue rate and noticed that the work queue rate was always high, and never really settled. The system was basically always running a reconciliation.
This was not the performance we were hoping for. Now the hunt to find the cause started. We did a lot of Googling and eventually found that Flux v2 had to go through the entire queue for each commit to the mono repository. Had we used multiple repositories this would not have happened. The reason this happens in a mono repo setup is that one Kustomize file can reference another Kustomize file, so to be sure that all is reconciled, it has to go through all Kustomize files in a repository.
Now the choice was basically if we should cancel the upgrade or try and move forward with improvements. 8 minutes was not acceptable to us.
We had a couple of knobs to turn and we used our Grafana dashboard to monitor for changes in performance. For every change, we had to redeploy the controller. Our problem was that we did not get consistent results. Sometimes we would get better performance by turning a knob like concurrent XXX and other times we would not.
It turned out we had a bottleneck that outweighed the other bottlenecks in the system. Sometimes this big bottleneck would allow more throughput and other times less throughput, despite improving the bottleneck we were focusing on or not.
This bottleneck of bottlenecks - also called the constraint of the system, turned out to be CPU resources. The initial resource definition on the Kustomization controller was set as follows:
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 100m
memory: 64Mi
Grafana dashboard was important
Lets have a look at the actual CPU usage in Grafana:
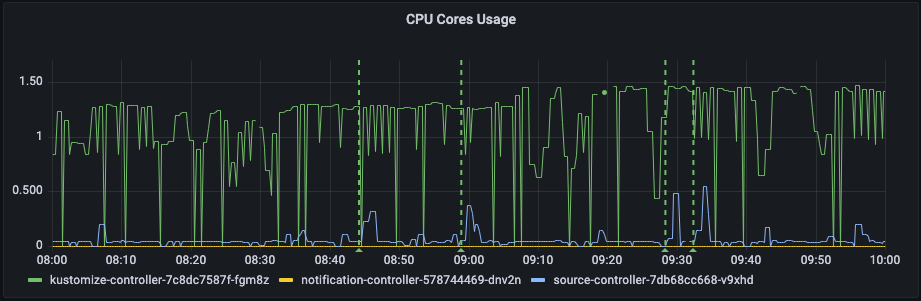
We can see that it flatlines a lot. And, another problem is that the Kustomization controller pod is scheduled based on the resources.requests field. So, sometimes it would get scheduled on a node where no CPU was used by other services and other times on nodes with heavy CPU usage.
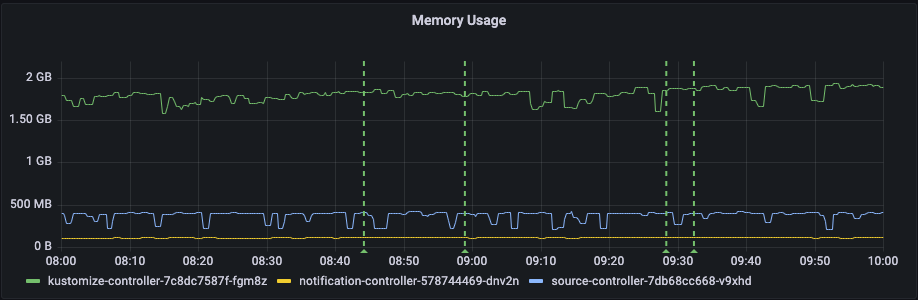
Looking at the memory consumption, we can see that it is quite stable so we did not have any concerns about memory.
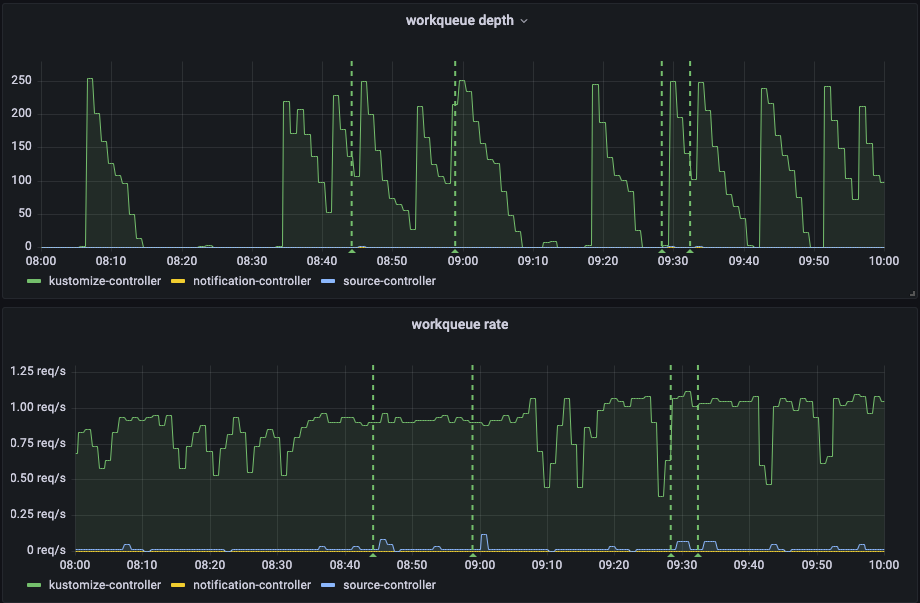
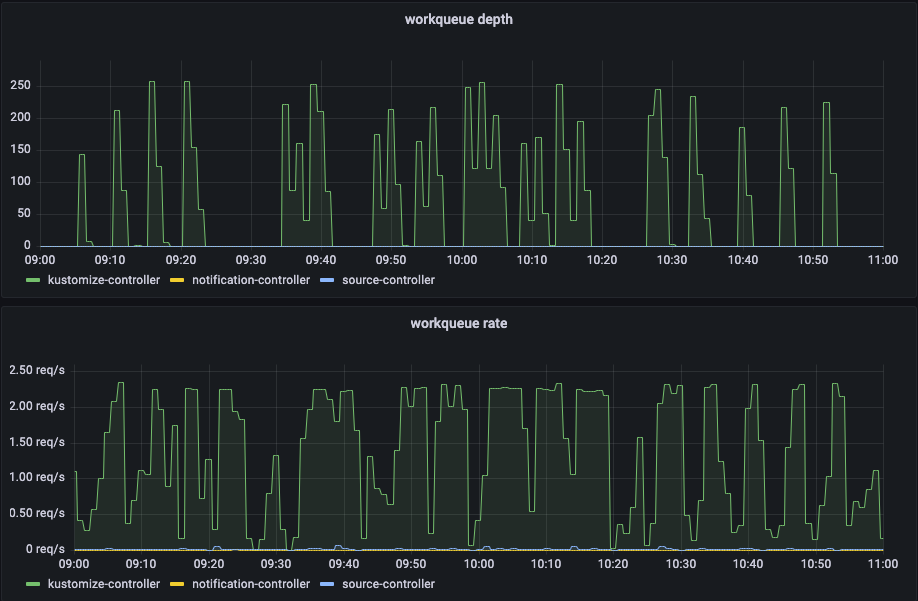
The graph showing the work queue depth and rate show each queue's start and end. On the work queue depth, we can see a peak every time someone releases a service. This is where Flux v2 will put all Kustomizations from that repository into the queue and start working its way through it. We can see that it takes roughly 8 minutes from start to end.
The work queue rate shows when it's actually doing something. It is using an average of more than two minutes. Flux v2 has an interval parameter that tells Flux how often it should re-check a Kustomization. By default, this is set to 5 minutes. So every 5 minutes, a service is being checked for changes. If you have more services than your Kustomization controller can process before the first service is set to be checked again, then you will always have work being done. It will never be at rest. This condition makes less room for the webhook reconciliation as well, so we sought to change this from 5 minutes to 10 minutes intervals.
We use small nodes (m5.large), which have 2 vCPU and 8 GB memory. To solve the CPU usage problem, we decided to put Flux v2 on a dedicated node (m5.xlarge) 4 vCPU and 16 GB memory in the cluster. This way we could ensure Flux the resources it needs. The CPU request is set to 3, and from the following graph, we can see that it utilizes that. There are also some daemonsets running on each node which is why it does not use all of the CPUs.

To get control of the memory usage, we set the request and limit to 3 G. As we can see here it does not necessarily use it all.
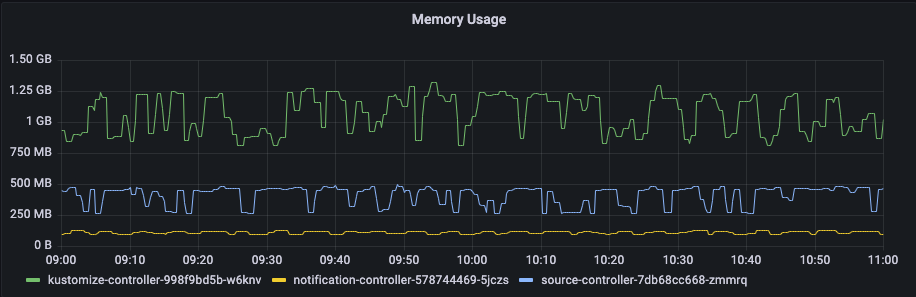
As seen on the following screenshot, the changes we made to our Flux 2 deployment meant that a system reconciliation (workqueue depth) now takes 2-3 minutes to process instead of 8 minutes.
Also, the workqueue rate shows that it actually has a chance of getting through the queue before a new reconciliation is promised.
Here are the changes we made:
> Kustomize controller interval went from 5m to 10m > Flux running on a dedicated node with more resources > kube-api-qps - default 20 - now 250 - QPS to use while talking with kubernetes API. > kube-api-burst - default 50 - now 500 - Burst to use while talking with kubernetes API server. > Removed CPU limit > Set CPU request to 3 > Set memory request and limits to 3G
Conclusion
In the end, the migration was good for us as it solves some of the pains we had with Flux v1, e.g. bulkheading and duplicate definitions. It also makes it possible to describe the order services are deployed in. For example, RabbitMQ will be deployed before microservices.
Flux v2 is very different from Flux v1. Therefore, we recommend that you play around with it before upgrading. The only thing Flux v1 and Flux v2 have in common is the name. Flux v2 is more complex, flexible, and extendable but introduces a higher risk from an operational point of view. At one point we killed one of our dev clusters while experimenting, as we wanted to move the main Kustomize manifest from the flux-system namespace to a different namespace. It introduced a race condition that ended up deleting the flux-system namespace before creating it again. With Flux v1 this isn't a problem, but we have all our Kustomize CRs in that namespace, and the Kustomize controller saw the deleting resources before closing down. When it does so, it will remove the services described in the Kustomize CR. As a result, Flux v2 deleted all services in that dev cluster.
One learning we can share is to scale the Kustomize controller to zero if you want to do anything related to Kustomize resources, flux-system namespace, etc.
Flux v2 requires more compute resources than Flux v1 in our case, so we ended up using a dedicated worker node. This is partly because we have a mono repository, which on every commit will trigger a reconciliation on all services. If we had multiple repositories it would only reconcile services in the given repository.
Next steps
Dependency management between Kustomization will be a huge help between our platform squads to create a boundary that is understood by each squad. This will make it easier for us to do failovers between clusters, as it will remove manual steps that currently control the order of deployment. It will also make it clear what each squad will deliver as a product to its customers.
We are in the middle of splitting up our platform squad into two squads, and with Flux v2 we can create a Kustomization for each of these. The Kustomization resources then point to services delivered by the squads and can have dependencies underneath it. These high-level Kustomization resources can then depend on each other so that resources by the Container Platform squad will be deployed before the Application Platform squad.
A great resource for inspiration can be found here: fluxcd/flux2-multi-tenancy.
NOTICE: Originally posted on January 19th 2022.